




2020 年 09 月 27 日
HA クラスタ超入門(後編)
HA クラスタ超入門の前編では、HA クラスタに関する用語や仕組み、導入のメリットなど、基礎的なポイントを解説しました。今回の後編では、HA クラスタソフトウェアを選択する際の重要なポイントや、前回簡単に説明した二重化できるソフトウェアの種類や検出可能な障害について、MIRACLE CLUSTERPRO での実装例を交えながら少し踏み込んで解説します。
Q. HA クラスタソフトの重要ポイントって?
A.
HA クラスタソフトとは、「運用系で障害が発生した場合、待機系に業務を引継ぐ ( フェイルオーバーする )」ことを主目的としたソフトウェアです。
以下のような点が HA クラスタソフトの重要ポイントになります。
- ( 二重化 ) 多重化できるソフトウェアの種類
- 検出可能な障害
- 運用時の利便性
以降では上記の各項目について Q&A 形式で説明していきます。
Q. 二重化できるソフトウェアの種類は?
A.
前編で簡単に一覧を記載しましたが、今回はもう少し掘り下げて説明します。
クラスタウェアでアプリケーションをフェイルオーバーさせるためには、当然、「クラスタウェアからそのアプリケーションの起動・停止が行える」ことが必要になります。
クラスタウェアでは一般的にアプリケーションをスクリプトから起動・停止させます。通常の deamon 等は当然、この方法で起動・停止が可能です。つまり、 GUI 画面のボタンからしか起動できないような、「スクリプトからの起動・停止ができない」アプリケーションは、二重化不可です。
また、運用系から待機系に業務データを引継ぐ際、「データ自体にマシン依存性があり、運用系で作成したデータは待機系で使えない」ようなアプリケーションも二重化できません。
Q. 具体的に検出可能な障害は?
A.
HA クラスタソフト毎に特徴がでる部分ですので、MIRACLE CLUSTERPRO での実装を中心に説明します。まず、HA クラスタが検知できる障害は大きく「自サーバーの障害」「相手サーバーのダウン」に分類できます。
まずは、自サーバーの障害についてですが、図 1 のような箇所の監視が可能です。

図1:検出可能な障害(自サーバー )
- アプリケーション死活監視
一般的な死活監視で、対象アプリケーションの PID が消失してないかどうか監視します。 - アプリケーション状態監視
それぞれのアプリケーション毎により適切な方法で監視を行います。RDBMS なら、実際に監視テーブルに対して書き込み / 読み込みを行い、データベースが健全かどうか監視します。この仕組みにより死活監視だけでは不可能な、アプリケーションのストールや結果異常も検出できることになります。MIRACLE CLUSTERPRO ではオプション製品でこの状態監視機能を提供しており、対応アプリケーション (daemon) は以下のとおりです。
- データベース (Oracle, MySQL, PostgresSQL, MariaDB, DB2)
- アプリケーションサーバー (WebLogic, WebSphere, Tuxedo)
- インターネットサーバー (HTTP, STMP, POP3, IMAP4)
- ファイルサーバー (Samba, NFS)
- 自己監視
クラスタウェア自身の監視機能です。クラスタウェアは自身もアプリケーションの一つとして監視することが一般的です。
MIRACLE CLUSTERPRO では図 2 のように、以下の自己監視機能があります。
- モジュール自身の動作監視
- モジュールの死活監視
- ユーザ空間のカーネル空間からの監視
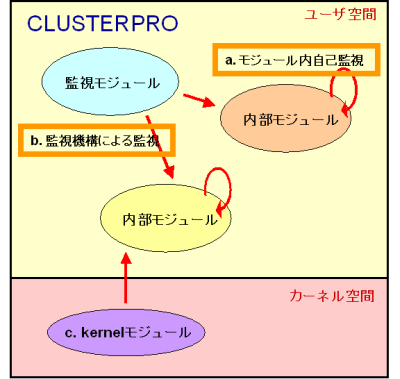
図2:自己監視 - OS 監視
OS 自体が健全に動作しているかどうかの監視機能です。MIRACLE CLUSTERPRO では自己監視機能の一つとして機能している③ -c のカーネル空間からの監視によって OS 自体も監視しています。 - ネットワーク監視
サーバのネットワークが健全かどうか監視する機能です。一般的には Gateway 等の機器に ping を発行することで、導通確認を行うことで行います。
MIRACLE CLUSTERPRO では上記に加え、NIC の Link up/down の状況を監視することも可能です。Geteway 等の外部機器を利用する必要が無いため、より柔軟なネットワーク監視が可能になります。 - ディスク監視
ディスクの監視を行う機能です。共有ディスクの監視を行うことが一般的ですが、 MIRACLE CLUSTERPRO では同手法でサーバーのローカルディスクを監視することも可能です。
MIRACLE CLUSTERPRO は、以下のようなディスク監視方法を選択できます。
- READ (O_DIRECT)
- READ (RAW)
- WRITE
- TUR
続いて相手サーバーのダウン監視機能(ハートビート機能)について説明します。
相手サーバがダウンした場合、生存しているノードで自発的に業務を引継ぐ必要があり、どういった方法で相手サーバダウンを検出するか、といったポイントが重要になります。
MIRACLE CLUSTERPRO では、図 3 のように、以下の 4 つの経路を設定することができます。- Ethernet ( 必須 )
- 共有ディスク
- RS-232C
- Witness サーバ
複数のハートビートを使用することで、単一デバイスの故障によるサーバーダウンと断線の誤認といった事象を防いでいます。
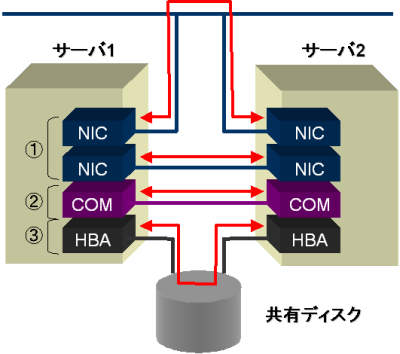
図3:検出可能な障害(相手サーバ)
Q. HA クラスタ運用時のポイントは?
A.
HA クラスタは「サーバー ( 業務 ) が健全に動作している」間はあまり役割はありません。サーバー ( 業務 ) の異常発生時にこそ、その真価が問われることになります。滞りなく業務が引継がれる ( フェイルオーバー) されることは当然ですが、その他にも、次の点が重要なポイントとなります。
- 異常発生時に的確にユーザに通知されること
- 異常発生後の調査性





