




2020 年 10 月 26 日
AWS の可用性の向上例を見てみよう! ~ 1. EC2 インスタンス単体で行う可用性の向上 ~
前回の記事 では、クラウドを使用した場合にも障害対策が必要であるということを紹介しました。今回からはいよいよ、障害対策を構築例と共に紹介していきます!本記事では詳しい構築方法は記載せず紹介のみとなりますが、最終回でダウンロードできるホワイトペーパーには記載しますので、どうぞご期待ください。
さて、今回の記事では、AWS 上の EC2 インスタンス単体で行う可用性の向上を、次の 2 つの方法で行っていきます。
- AWS のサービスのみで実現する可用性の向上
- 監視・復旧ソフトを使用した可用性の向上
それぞれの方法について記事の後半で詳しく比較・解説していきます!
AWS のサービスのみで実現する可用性の向上
まずは、AWS のサービスのみで実現する可用性の向上について紹介します。この方法では、CloudWatch というサービスを使います。CloudWatch については次の項目で詳しく説明しますが、EC2 インスタンスなどの各種 AWS リソースの監視を行うサービスです。構成は大まかに、CloudWatch で監視を行い、異常発生時にインスタンスの再起動を行うというものです。
CloudWatch とは
CloudWatch とは AWS で提供されているサービスの一つです。このサービスでは AWS の各種リソースの監視を行うことが出来ますが、今回は主に EC2 インスタンスの監視について紹介します。CloudWatch の監視項目はメトリクスと呼ばれ、標準ではシステム情報やインスタンスのステータスチェックなどを監視することが出来ます。さらに、CloudWatch Agent というエージェントをインスタンスに導入することで、詳細なシステム情報や、プロセスの情報の監視も可能となります。メトリクスの値は、AWS マネジメントコンソール上から確認することが出来ます。
また、CloudWatch では、メトリクスにアラームというものを設定することが出来ます。このアラームは、メトリクスの値が設定した条件を満たしたときに、設定した動作を行わせることが出来るというものです。今回はこのアラームを使い、可用性の向上を行っていきます。
構成
構成は次の画像のようになります。この構成では、指定したプロセス名の検出数が、事前に設定した下限値を下回った場合に、障害と判断します。そして、障害時の動作としてインスタンスの再起動を行います。
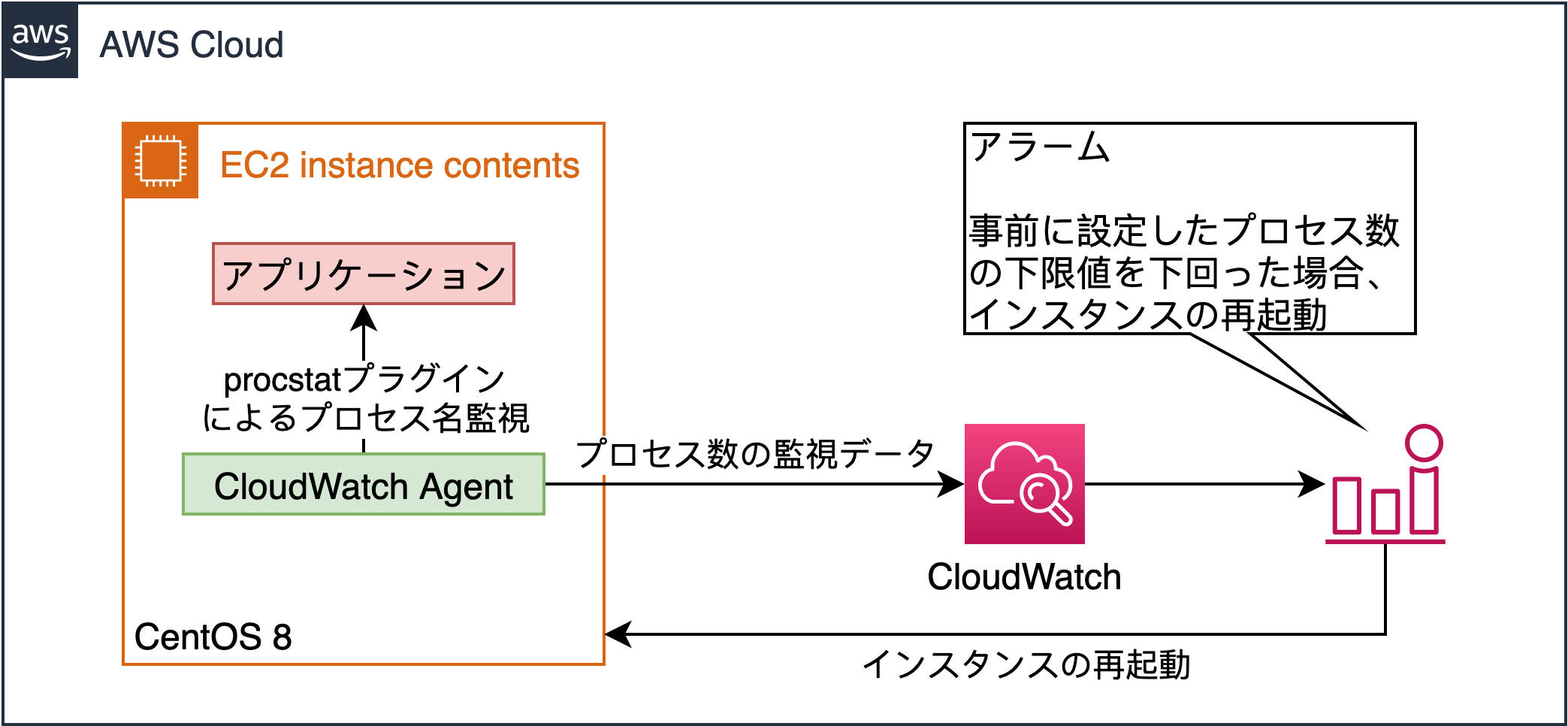
各項目について詳しく説明します。まず、アプリケーションの監視を行うために、EC2 インスタンスに CloudWatch Agent を導入します。CloudWatch Agent によって監視されたプロセス数のデータは、CloudWatch にメトリクスとして送信されます。そして、CloudWatch 側でアラームを設定することで、事前に設定した下限値を下回った場合に、インスタンスの再起動という動作をさせることが出来ます。
大まかな構築方法、実際の動作画面など
この構成の大まかな構築方法は、
- EC2 インスタンスに監視対象となる環境を構築
- EC2 インスタンスに CloudWatch Agent を導入
- CloudWatch Agent の設定ファイルを作成
- AWS 側でアラームの設定
となります。この構築方法から分かるように、AWS のサービスのみで完結しています。
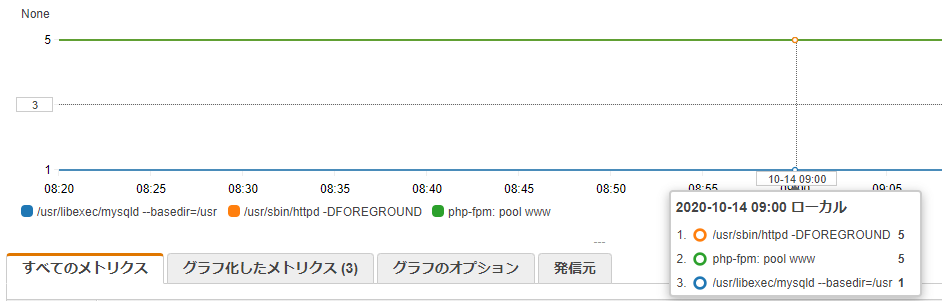
それでは、実際の動作画面を紹介します。この環境では、LAMP 環境を構築し監視を行っています。CloudWatch Agent を使い、Apache HTTP Server, MariaDB, PHP のそれぞれのプロセス数を監視しています。下の画像のように、AWS マネジメントコンソール上からメトリクスの値を確認することが出来ます。
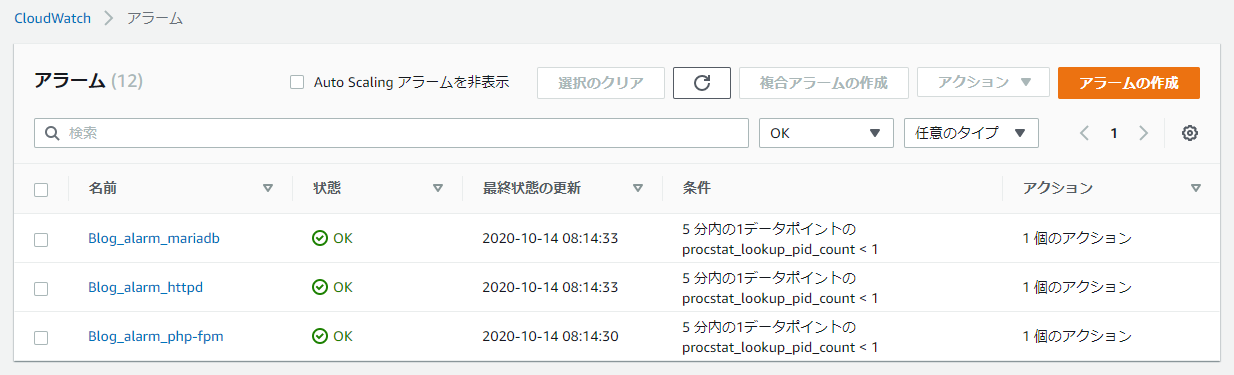
ここで、アラームを設定します。アラームはそれぞれのプロセス数のメトリクスに対して 1 つずつの、計 3 つ作成します。アラームの条件は
- 異常と判断する下限値は:1
- 異常時の復旧動作:対象インスタンスの再起動
と設定します。通常時は 1 つ以上のプロセスが存在するため、下の画像のように正常と判断されます。
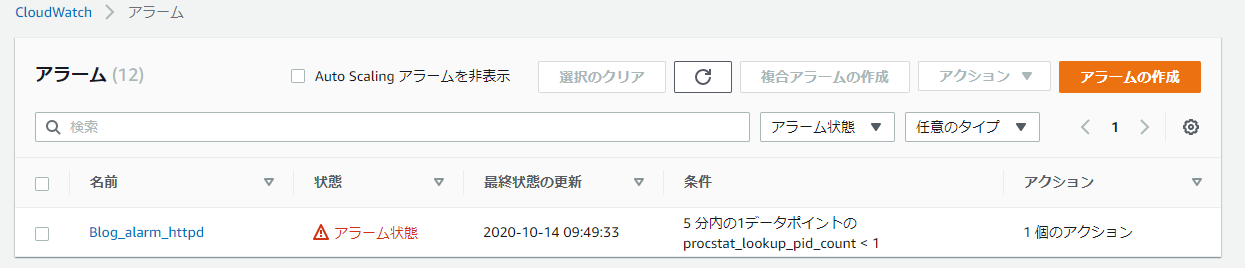
では、実際にアプリケーションを止めて、再起動が行われることを確認してみます。SSH でログインし、 Apache HTTP Server のサービスである httpd を停止させます。少し待つと以下のように、httpd のアラームが異常状態となります。
このとき、インスタンスの再起動が行われています。そのため、また少し待つと、再起動によりアプリケーションが起動し、アラームが正常状態へと戻ります。アラームの対象としているメトリクスをグラフ化すると、実際に、異常検知、インスタンス再起動と動作していることが確認できます。
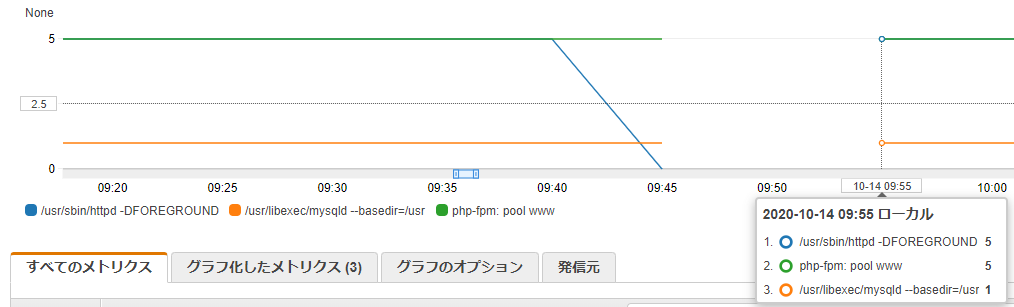
このようにして可用性を高めることが出来ます。
特徴
まず、この方法の場合、プロセス情報の監視を行う必要となるため、CloudWatch Agent の導入が必須となります。また、CloudWatch Agent を導入するため、設定ファイルの作成が必要となります。この点に関しては、エージェントの導入の必要ないシステム情報を監視する場合と比べ、手間となってしまいます。しかし、エージェントの導入だけで行えるため、AWS のサービスのみで完結することが出来るという特徴もあります。
また、この方法には異常時の復旧動作が限られるという問題があります。アラームから直接行えるインスタンスの復旧動作は、インスタンスの停止、削除、終了などに限られます。そのため、CloudWatch を使った方法ではアプリケーションのみに障害が発生した場合でもインスタンス全体の再起動が必要となってしまいます。
監視・復旧ソフトを使用した可用性の向上
次に監視・復旧ソフトを使用した可用性の向上について紹介します。この方法では弊社製品の MIRACLE FailSafe for CentOS というソフトを使用します。詳細については次の項目で説明しますが、システムの監視・復旧を行い、可用性を向上させるソフトとなっています。構成は大まかに、MIRACLE FailSafe for CentOS で監視を行い、異常発生時に事前に設定した復旧動作を自動で行わせるというものです。
MIRACLE FailSafe for CentOS とは
MIRACLE FailSafe for CentOS はシステムの可用性の向上を目的とし、CentOS を対象としているソフトウェアです ( 以降 MFS とします )。システム情報やプロセスの監視に加え、OS や MFS 自体の自己監視など、より様々な項目の監視を行うことができます。さらに、監視項目や異常が発生した際の復旧動作を、詳細に設定することが出来ます。今回はこの詳細な復旧動作を設定できるという特徴を活かした構成を行います。
構成
構成は次の画像のようになります。この構成でも、CloudWatch の場合と同じように、プロセス名の検出数が事前に設定した下限値を下回った場合に障害と判断します。異なるのは、以下の点です。
- 異常時の復旧動作がアプリケーションのみの再起動
- インスタンス内で完結している
- MFS は自己監視、及び OS 監視を行っている
これらは、
- 詳細な監視・復旧設定が行える
- 豊富な監視項目
といった CloudWatch にない特徴を活かしたものとなっています。

大まかな構築方法、実際の動作画面など
この構成では、AWS 側のサービスで設定することはありません。そのため、EC2 インスタンスへの MFS のインストール、MFS の Web UI 上での設定が主な構築となります。そのため、大まかな構築方法は、
1. EC2 インスタンスに監視対象となる環境を構築
2. EC2 インスタンスに MFS を導入
3. MFS 上で監視、復旧時の動作設定
となります。
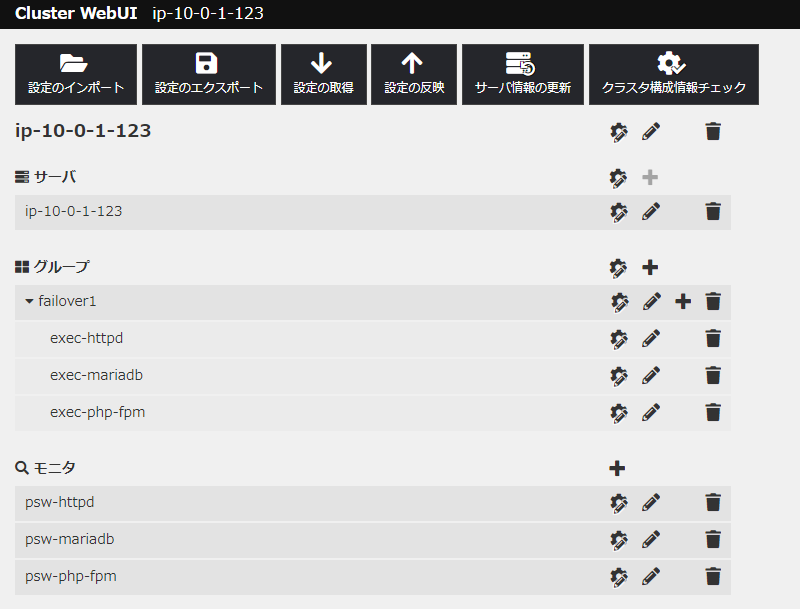
それでは、実際の動作画面を紹介します。この環境では、同じく LAMP 環境を構築し監視を行っています。MFS をインストール後、設定は下の画像のように Web UI 上から行うことが出来ます。下の画像では、LAMP 環境の各アプリケーションを起動するための exec から始まる設定と、各アプリケーションのプロセスを監視するためのモニタが設定されています。
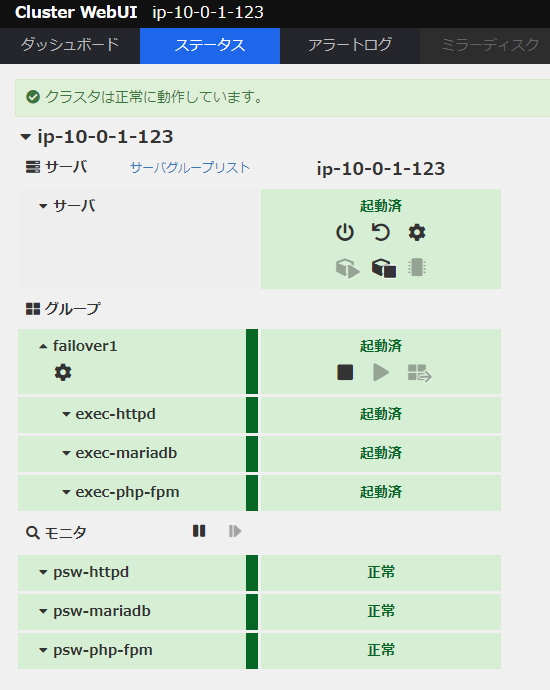
設定後、起動すると、設定に沿って各アプリケーションの起動が行われます。Web UI からは、以下の画像のように各監視項目の状況を確認することが出来ます。これは起動後の、全てが正常な状態です。
では、実際にアプリケーションを止めて、アプリケーションみの再起動が行われることを確認してみます。SSH でログインし、 Apache HTTP Server のサービスである httpd を停止させます。すると httpd のプロセス数が 0 となり、以下の画像のように下限値を下回ったことを MFS が検知します。検知後は直ちにアプリケーションの再起動を行います。今回の場合、検知からアプリケーションの再起動までは十数秒しかかかりません。再起動後は先程の正常な状態へと戻ります。

特徴
この方法の場合、MFS のインストールが必要となりますが、MFS インストール後の設定等は全て Web UI で容易に行うことが出来ます。そのため、CloudWatch Agent を導入した場合の設定ファイルの作成と比べても、全体的な手間はあまり変わりません。
この方法では、復旧動作をより詳細に指定出来るようになるため、アプリケーション単位での再起動が可能となります。これにより、素早い検知と合わせ、ダウンタイムを最小限に留めることが出来ます。インスタンスの再起動と比べ、アプリケーションのみの再起動ではダウンタイムは大幅に短縮されます。さらに、MFS は OS、MFS 自身の監視を行うため、アプリケーション以外の部分の可用性も向上することが出来ます。
比較
それでは今回紹介した 2 つの方法の比較を行っていきます。各種機能や大まかな料金についての比較は、以下の表のようになります。
|
CloudWatch による方法 | MIRACLE FailSafe による方法 |
|---|---|---|
インストール |
詳細な監視を行うには |
必須 |
監視の設定方法 |
エージェントを導入する場合、 |
Web UI で容易に行える |
監視情報の確認 |
AWS マネジメントコンソールから可能 |
Web UI から可能 |
監視項目 |
など。エージェントにより、
などが追加で監視可能。 |
など。 |
監視の設定項目 |
主に監視インターバルのみ |
監視インターバルに加え、 |
復旧時の動作 |
停止 , 再起動などの 後述する Auto Scaling も |
詳細な設定が可能
|
ダウンタイム |
インスタンスの再起動の時間 |
設定により最小限にできる |
料金 |
監視項目の数やアラームの精度による従量制。 |
1, 3, 5 年の買い切り制。 |
サポート |
ビジネスプラン等に |
サポート込み。 |
概算 |
¥10,150 ~ / 月 |
¥6,650 / 月 |
CloudWatch による方法では、簡易的な可用性の向上であればすぐに行えるという特徴があります。そのため、複数台のインスタンスによる、負荷分散が可能なシステムの構成に向いていると考えられます。これは、単体のインスタンスの障害によるシステム全体への影響が、それほど大きくないと推測されるためです。具体的な構成は、複数台のインスタンスに簡易的な可用性の向上を行い、障害が発生した場合はそのインスタンスのみを再起動するというものになります。簡易的な可用性の向上は、CloudWatch Agent のインストールが必要ない方法を指します。これは、設定ファイルの作成までの手間を考えると、MFS による方法のほうが Web UI 上で容易にかつ高度な設定を行うことが出来るためです。AWS Auto Scaling というサービスを、アラーム時の動作として設定することにより、可用性をより向上することも出来ます。
MFS による方法でも、CloudWatch と同様に、複数台構成による負荷分散システムを構築することが可能です。しかし、それに加えて、MFS には高度な可用性の向上を容易に行えるという特徴があります。そのため、負荷分散の難しい、スタンドアロンなシステムの構成にも向いていると考えられます。これは、障害の発生時の復旧にかかる時間が、そのままシステムのダウンタイムに直結するためです。MFS では、詳細な設定により、復旧にかかる時間を最小限に留めることが可能です。今回紹介した例のように、アプリケーション単位の再起動で済む場合は、インスタンスの再起動と比べ大幅な短縮となります。また、この特徴により、マシンの再起動を極力避けたい環境の場合にも使用することができます。さらに、それらの詳細な設定がかつ Web UI 上で容易に行えるという点も大きな特徴となっています。こちらの方法でも、工夫をすることで Auto Scaling との併用も可能となり、単体のまま可用性をより向上することができます。この応用版のシステム構成については、最終回で紹介予定です。
まとめ
今回は単体のインスタンスの可用性の向上について紹介しました。紹介した 2 つの方法ですが、比較の項目でお話したようにどちらにも向いている用途があり、システムの要件よって選択することが重要となります。高度な可用性の向上に興味がある場合は、ぜひ MFS を視野に入れてご検討ください!
今回紹介した方法以外の可用性を向上させる構成について、今後も紹介していく予定です。まず、次回は弊社製品 MIRACLE CLUSTERPRO X を使用した、クラスター構成について紹介します。クラスター構成は、2 つ以上のサーバーを用意することで、可用性をさらに向上させる手法となっています。次回もどうぞご期待ください!






